
Elusive Bugs with GraphQL Object Caching in Apollo Client
We are deploying a major update to our internal application soon that uses the Apollo client for GraphQL. It's pretty awesome even though there were a couple bugs I had to fix.
During regression testing we ran into an issue involving the Apollo client that was subtle and caused "interesting" bugs. First, let's take a look at exactly how object caching works.
Caching in Apollo client
By default, caching in Apollo uses the in-memory cache. The way Apollo determines if it should cache a GraphQL object is if the response contains an id or _id property and a __typename property (which is added automatically by Apollo by default).
So, for example, let's say we declared a Product type in our GraphQL schema:
type Product {
sku: ID!
title: String!
quantity: Int!
}
The product has an identifier and it's stored in the SKU field.
Then you issued a query like this:
{
product(sku: "abc123") {
sku
title
quantity
}
}
Pretty straightforward--we want to grab the sku, title, and quantity for a product by SKU. The response when run through Apollo client will look like:
{
data: {
product: {
sku: "abc123",
title: "My cool product",
quantity: 4,
__typename: "Product"
}
}
}
Now, based on the rules above, do you think Apollo will cache the Product object by it's SKU? No. Because there is no id or _id property, only a __typename property which isn't enough.
We can fix this in a few ways:
- Change the schema
- Use
dataIdFromObjectoption in the caching configuration - Alias the SKU to be
id - Alias SKU as
_idbut still keepsku
I don't like the first option because if sku is the natural key in your domain, why change it?
Using dataIdFromObject is a great approach if you control the client configuration:
import { InMemoryCache, defaultDataIdFromObject } from 'apollo-cache-inmemory';
const cache = new InMemoryCache({
dataIdFromObject: object => {
switch (object.__typename) {
case 'Product': return object.sku; // use `sku` as the primary key
default: return defaultDataIdFromObject(object); // fall back to default handling
}
}
});
I'd advise splitting this up into separate functions for each type and genericizing it but I leave that up to you.
If you don't control the configuration, adding an alias still allow you to express what the natural ID is of your domain objects and pushes the concern of ID caching to the client.
I prefer adding an additional _id field because it allows our caller to still treat the response as it would be expected from the GraphQL documentation. It also helps more if you're statically typing responses. With that in mind, let's update our query:
{
product(sku: "abc123") {
sku
title
quantity
_id: sku
}
}
Great! We've added an alias for _id so now GraphQL will respond with:
{
data: {
product: {
sku: "abc123",
title: "My cool product",
quantity: 4,
_id: "abc123",
__typename: "Product"
}
}
}
Now the condition is satisfied and Apollo will cache the Product by this ID.
Non-idempotent object caching
Using IDs is pretty standard when working with APIs and data. Real scenarios have more complex data and thus your GraphQL schema will probably start to get more involved. Since many entities in an application domain might have id properties this feature of Apollo can also turn against you if you aren't careful.
For example, let's say a product can come in multiple colors. On a per-product basis, you can mark a color as the primary color--meaning for example by default when shown on your website, you present that color first. But the names of colors are static and are on a per-color basis.
The schema looks like:
type Color {
id: Int!
name: String!
is_primary: Boolean!
}
The GraphQL query will look something like this if you're working with a standard id convention:
{
product(sku: "abc123") {
_id: sku
sku
title
quantity
colors {
id
is_primary
name
}
}
}
Again this is pretty straightforward and nothing looks wrong on the surface. But it hides a subtle and nasty issue. When Apollo sends this query and the server will respond like this:
{
data: {
product: {
sku: "abc123",
title: "My cool product",
quantity: 4,
colors: [
{ id: 1, name: "Red", is_primary: true, __typename: "Color" },
{ id: 2, name: "Blue", is_primary: false, __typename: "Color" }
],
_id: "abc123",
__typename: "Product"
}
}
}
Now think about the conditions in which Apollo will cache a Color object. Do you see the problem? Let me showcase the problem by issuing multiple product queries that select primary colors:
{
products(skus: ["abc123", "xyz890"]) {
_id: sku
sku
title
quantity
colors {
id
is_primary
name
}
}
}
Now the raw GraphQL response looks like this for multiple products:
{
data: {
products: [
{
sku: "abc123",
title: "My cool product",
quantity: 4,
colors: [
{ id: 1, name: "Red", is_primary: true, __typename: "Color" },
{ id: 2, name: "Blue", is_primary: false, __typename: "Color" }
],
_id: "abc123",
__typename: "Product"
},
{
sku: "xyz890",
title: "Another cool product",
quantity: 0,
colors: [
{ id: 1, name: "Red", is_primary: false, __typename: "Color" },
{ id: 3, name: "Yellow", is_primary: true, __typename: "Color" }
],
_id: "xyz890",
__typename: "Product"
}
]
}
}
But when Apollo processes these query results, it tries to be smart and efficient by attempting to read objects from the cache. Guess what will happen as it processes this?
- Process
products[0] - Cache product by ID
abc123for typeProduct - Process
products[0].colors[0] - Cache color Red by ID
1for typeColor
At step 4, we've cached the Red color by its ID, which means when Apollo moves to the next product...
- Process
products[1].colors[0] - Does color Red
1already exist in the cache? YES. Reuse that object.
Let's look at the actual response Apollo gives us for this same query:
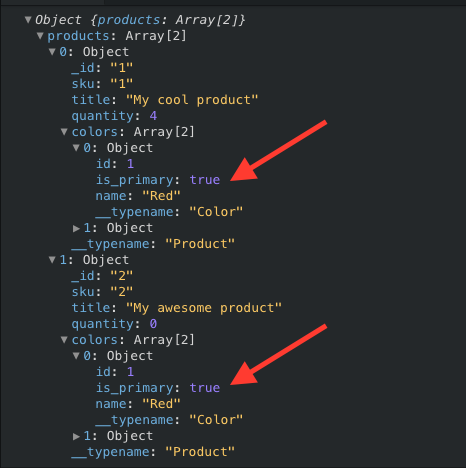
See for yourself!
Apollo "smartly" reuses the same object response for Red as before--which means when we read the Apollo query result, the second product ends up having no primary color. OOPS.
The root cause
While this may seem like a bug, it's not really--it's just showcasing an issue with the way we are expressing our GraphQL types incorrectly. Apollo is making the assumption that an entity is idempotent across queries with the same ID. In our case, that's not true because different products may have different is_primary values for the same color. Ideally, what we should be doing is putting all product-specific information on the Product type, not a nested type.
Workaround or fix it?
The right way to fix this is by changing our schema to add a new primary_color field to the Product type:
type Product {
sku: ID!
title: String!
quantity: Int!
colors: [Color]!
primary_color: Color
}
type Color {
id: Int!
name: String!
}
Now for any number of products, Color can be safely cached no matter where it appears in a response.
In some cases, like ours, doing the right thing is a large enough change that we can't do it right away without modifying a lot of client code (we could migrate slowly, by adding the new field and deprecating the old field). It's also just possible in a big company, you may not control the schema and have to wait for a fix from another team. There are some other workarounds you as a client can do.
Alias the ID as something else
The first workaround is to simply just use a different field name instead of id:
{
products(skus: ["abc123", "xyz890") {
_id: sku
sku
title
quantity
colors {
color_id: id
is_primary
name
}
}
}
Apollo's caching condition won't trigger for the Color objects now (no id or _id fields) and we're safe.
This might seem like a good approach but the downside is that it would be easy for a future developer to mistakenly use id in another query and not realize the mistake they're making.
Exclude the __typename field
It might be better to just explicitly exclude the __typename field that Apollo adds by default. It turns out this is pretty easy and makes it very apparent we are doing something "weird" that should cause future developers to stop and ask why:
{
products(skus: ["abc123", "xyz890"]) {
_id: sku
sku
title
quantity
colors {
color_id: id
is_primary
name
# Disable Apollo caching for this Color
__typename @skip(if: true)
}
}
}
Using the @skip GraphQL directive, we can explictly denote we don't want to cache the response for this particular query result for Color. We can even call it out with a comment to make it extra apparent.
Don't add __typename wholesale
If you control your Apollo client caching, there is an option to disable automatic addition of __typename to queries for the in-memory caching using the addTypename: false option.
If you wanted to disable caching wholesale, it's probably better to just use the no-cache fetch policy which bypasses any calls to the underlying data store (which can be expensive for very large query batches/responses).
Caching is awesome except when its not
This "bug" took us awhile to figure out--but I remember reading the docs for Apollo caching and after I tested aliasing the fields, everything was suddenly working as expected, that's when it clicked more and I understood what was happening. I love GraphQL and the Apollo client is pretty awesome but issues like these can be frustrating! I hope this breakdown helps other GQL developers model their schema appropriately.
The reference code is available on:
- Apollo Launchpad: https://launchpad.graphql.com/kqx178pn57
- Codesandbox: https://codesandbox.io/s/24zx7k6z10